Are the Data Lakes Delivering on the Promise?

Over the last decade, the data lakes have evolved to become a very popular infrastructure pattern for managing big data. Data lakes were introduced to overcome the challenges associated with traditional data warehouses such as slowness in data source integration, inability to capture unstructured and semistructured data and the scalability of the infrastructure. More than a decade into evolution, the businesses are staring to question if the value is delivered by the data lakes. This article aims to discuss some drawbacks with data lakes and introduce some architectural designs emerging to address such problems.
What is a Data Lake?
The concept of a data lake was coined in 2010 by James Dixon, founder of Pentaho in one of his blog post that outlined his company’s first Hadoop-based release,
If you think of a datamart as a store of bottled water — cleansed and packaged and structured for easy consumption — the data lake is a large body of water in a more natural state. The contents of the data lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples
The basic philosophy of the data lake is to “store everything” and “use when required”. It differs from data warehouses which requires a schema to be defined before the data is ingested. The data lakes follow a schema on read approach where the data is ingested in their raw format and schema is enforced only when the data is accessed. This enables quick integration of data sources and the ability to capture semistructured and unstructured data in variety of formats. Another key advantage is the horizontal scalability which enables large volumes of data to be stored. The value generation from the data is expected to be faster as the data is consolidated and available in a single platform.
Taking a Deep Dive in to the Data Lake
With many advantages on offer, modern organizations have invested heavily on building data lakes to consolidate data from siloed systems and build data products which deliver value. However it has not been smooth sailing and there are many challenges that organizations are discovering throughout their data lake journey.
From Data Lake to Data Swamp
Unless there is strict governance in place, a data lake can easily become a data swamp, a dumping ground for volumes of data. Unlike in data warehouses, it is extremely difficult to catalog data making it very hard to keep track of what’s swimming in the data lake. This would mean that it is very complex to implement governance protocols such as access control, retention policies and privacy policies.
Consolidating data from siloed systems is no easy task. Data Lakes depend on metadata to derive relationships between various data segments and to establish data lineage. In absence of quality metadata, generating value from large volumes of data could turn out to be a a tedious task.
The “store now and use later” approach leads organizations to collect large volumes of data without a clear goal in mind. When this happens the data lake is flooded with data which provide no value and may never be used.
Ownership of Data
Who owns the data in a data lake? Usually a centralized IT or Engineering team is responsible for managing the data lake. However such teams lack domain knowledge on the data which makes it harder for them serve the end user demands. Often such teams are seen as a bottleneck in the value chain.
Also there is no contract with the domain data owners to contribute quality data sets to the data lake. This makes life harder for the team in the middle in serving the end user demands as they often have to deal with data quality issues originating from the data sources.
Delivering Value
Data swamps coupled with weak ownership of data can lead to serious problems in generating value out of the data lake. The challenges in data discovery and data quality at times outweigh the advantage gained during data ingestion and storage. A system that was built for faster insights may not deliver at the speed that it was suppose to, making the business leaders question the ROI.
The Changing Waters of Big Data
Organizations today are reevaluating their options in making sense out of big data. On one end they are looking at solutions which enforce stronger governance and ownership. On the other hand they are looking for solutions which are less data hungry. Here we look at some emerging trends that aims to address the type of problems discussed previously.
Data Mesh
Data Mesh is an architectural paradigm which promotes a domain driven model for managing data. The idea is for the teams with domain expertise to own their data and service the use cases through standardized APIs using a self service data platform. The key change in this model is the decentralization of the data ownership which leads to a value focused approach in managing data. There are four underpining principles of a Data Mesh implementation.
- Domain-oriented decentralized data ownership and architecture
- Data as a product
- Self-serve data infrastructure as a platform
- Federated computational governance
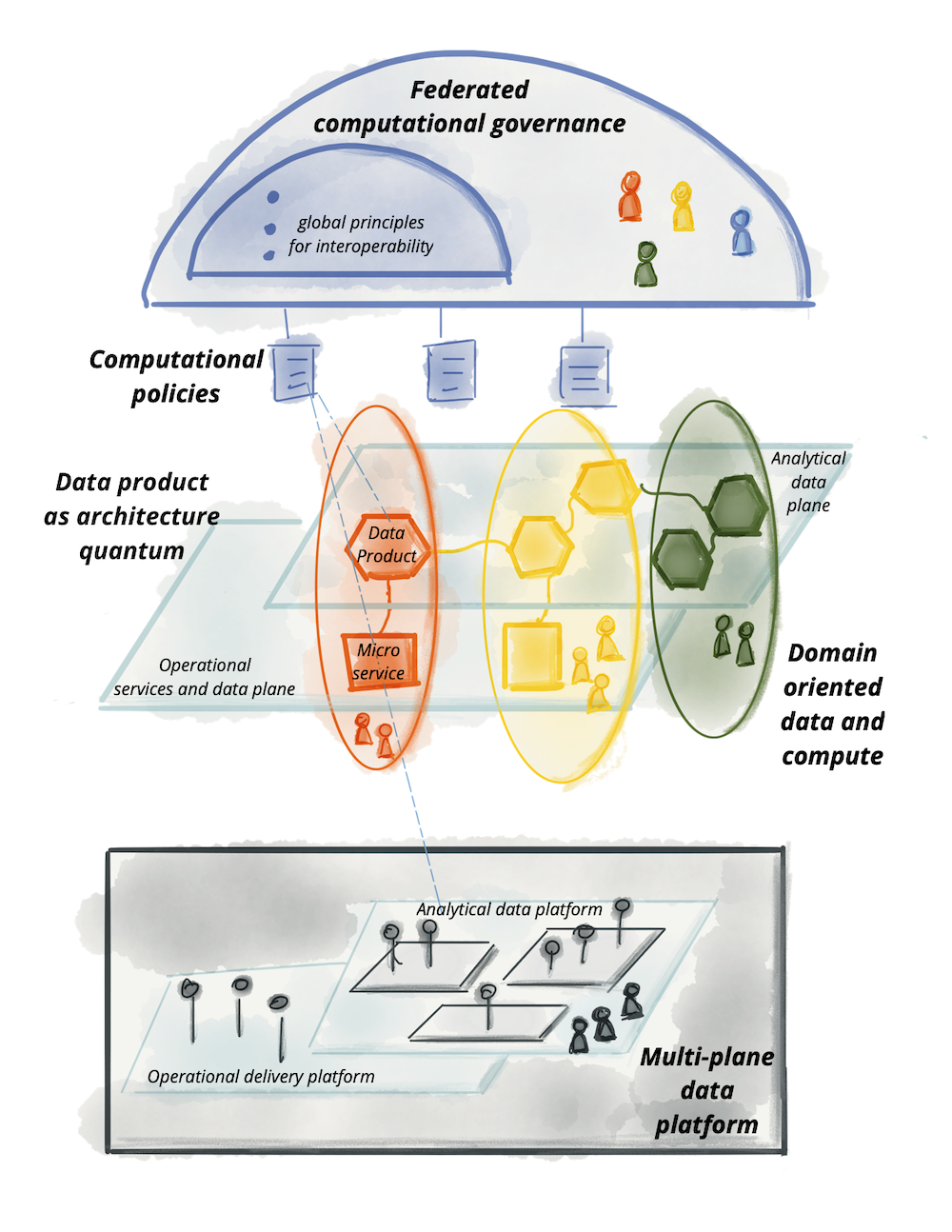
The big data technology landscape currently in practice would still be relevant in the Data Mesh context however more innovation can be expected in data access and governance use cases as the adoption increases.
Small and Wide Data
As per Gartner 70% of organizations will shift their focus from big to small and wide data by 2025. The fundamental idea with small and wide data is to use smaller but more focussed data sets from variety of data sources to make the inferences. The advantage of this approach is that the decisions can be made on a more real-time basis as big data processing is not involved.
One of the biggest drawbacks of big data is the ability to adapt to changing environments. A good example was when COVID lockdowns were imposed worldwide, the systems that depend on historical big data became less effective as the behavioral patterns altered drastically from the norm. It was an eye opener for the data community to consider alternative approaches for making sense out of data.
Big data often serves the purpose of building big picture ideas and in the process some of the more fine grained information that actually drives the behavior may be lost. Small and wide data approach aims to address this problem by capturing more specific details.
In the small and wide data approach, the investment is more focussed on value generation compared to big data where the investment is more focussed on the technology platform for data storage and processing.
Conclusion
It is very much likely that the next revolution of data would not be bigger data but more up to date and personalized data. The solutions that emerge would focus on generating value out of data rather than storing large volumes of data. However the approaches like Data Mesh and Small and Wide data are still at early stages and would be interesting trends to observer in the coming years.